FAQs
Wie wurden die Daten erfasst?
 Screenshot: Datensatz
Screenshot: Datensatz
Wir verwenden die Metadaten, die ursprünglich für die Suchmaschine des Österreichischen Bibliothekenverbundes erfasst wurden - also Katalogdaten. Die Katalogisate werden nach dem Katalogisierungsregelwerk RDA (Resource Description and Access) im bibliografischen Datenformat MARC 21 aufgenommen, mit der Basisklassifikation versehen, inhaltlich erschlossen, und die Verfasser bzw. die beteiligten Personen sind möglichst mit der GND verknüpft.
Was wird katalogisiert?
Titel, die in Inhaltsverzeichnissen bzw. in Kopfzeilen stehen. Ca. 366.000 digitalisierte Seiten werden nach ihrem Eintrag in Inhaltsverzeichnissen bzw. Kopfzeilen geordnet. So sind auch Absätze, die üblicherweise nicht katalogisiert werden, erfasst worden. Diese ungewöhnliche Vorgangsweise führt zu einer sehr hohen Anzahl von Katalogisaten. Die Katalogisierung des Datensatzes ist noch nicht abgeschlossen, neue Katalogisate werden laufend hinzugefügt.
Was ist eine Knowledge Map?
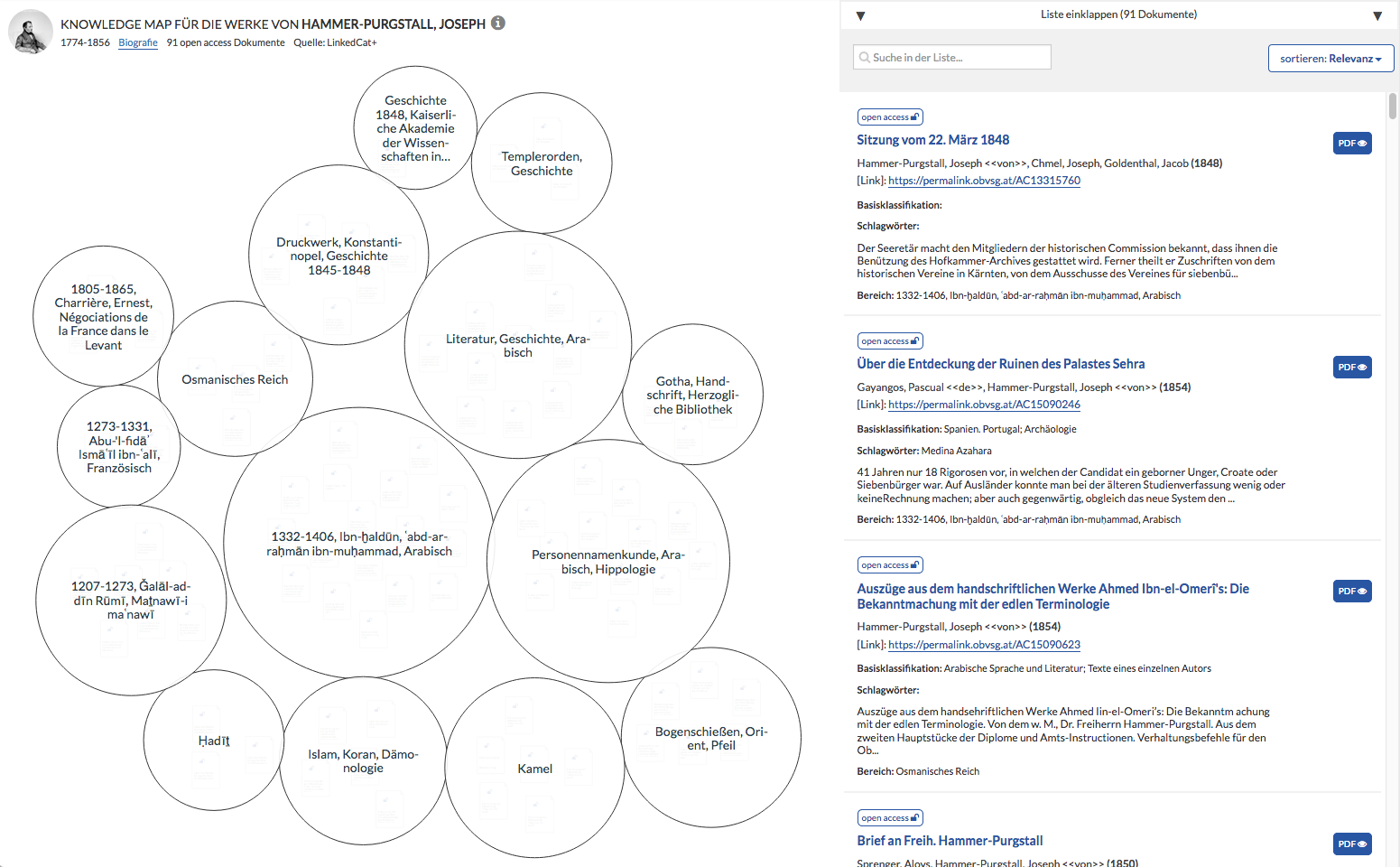 Screenshot: Knowledge Map für die Werke des Autors Hammer-Purgstall (Quelle: Linkedcat+)
Screenshot: Knowledge Map für die Werke des Autors Hammer-Purgstall (Quelle: Linkedcat+)
Eine Knowledge Map (zu deutsch "Wissenslandkarte") gibt einen thematischen Überblick über ein Stichwort/einen Autor. Unterthemen werden als Blasen dargestellt. Jedem Unterthema sind relevante Dokumente zugeordnet, die mit einem Klick auf die Blase angezeigt werden können. Ein Dokument wird in einer Knowledge Map nur einer Blase zugeordnet.
Knowledge Maps eignen sich besonders dazu, einen Überblick über ein Thema zu bekommen und relevante Konzepte und Dokumente zu entdecken. Die Größe der Blasen ist relativ zur Anzahl der zugeordneten Dokumente. Blasen, die sich thematisch ähnlich sind, werden näher zueinander dargestellt als Blasen, die sich thematisch weniger ähnlich sind.
Knowledge Maps haben ihren Ursprung bereits in den 1970er-Jahren. Weitere Informationen zu dem hier verwendeten Knowledge Map-Typ finden Sie in diesem Artikel; einen allgemeinen Überblick über bei Knowledge Maps verwendeten Verfahren finden Sie bspw. in diesem Artikel.
Was ist ein Streamgraph?
 Screenshot: Streamgraph für die Werke des Autors Hammer-Purgstall (Quelle: Linkedcat+)
Screenshot: Streamgraph für die Werke des Autors Hammer-Purgstall (Quelle: Linkedcat+)
Ein Streamgraph zeigt die zeitliche Entwicklung der häufigsten Schlagworte zu einem Stichwort/Autor. Die Schlagworte werden als farbige Ströme (Englisch "streams") dargestellt. Jedem Strom sind relevante Dokumente zugeordnet, die mit einem Klick auf einen Stream angezeigt werden können. Ein Dokument kann in einem Streamgraph mehreren Strömen zugeordnet sein. Es kann aber auch vorkommen, dass ein Dokument keinem Strom zugeordnet ist - und zwar dann, wenn das Dokument nicht mit einem der häufigsten Schlagworte annotiert ist.
Streamgraphen eignen sich besonders dazu, die Entwicklung von Schlagwörtern über die Zeit zu analysieren und Trends zu erkennen. Die Höhe eines Stroms entspricht der Anzahl der zugeordneten Dokumente zu einem bestimmten Zeitpunkt. Dabei ist zu beachten, dass die Anzahl der relativen, nicht der absoluten Höhe entspricht. Zwischen den Zeitpunkten wird der Strom interpoliert.
Da das für die Interpolation verwendete Verfahren noch nicht perfekt ist, kann es dadurch vereinzelt auch zu grafischen Artefakten kommen; das bedeutet, dass Ströme an Stellen kleine Ausschläge aufweisen, obwohl zu diesem Zeitpunkt keine Dokumente für das Stichwort vorhanden sind. Im Zweifelsfall können Sie dies überprüfen, indem Sie mit der Maus über den Strom fahren und sich die Anzahl der Dokumente anzeigen lassen.
Streamgraphen wurden im Jahr 2008 von Byron und Wattenberg ursprünglich für die New York Times entwickelt. Weitere Informationen finden Sie in diesem Artikel.
Was ist unter relevanteste Dokumente zu verstehen?
In diesem Projekt verwenden wir das Relevanz-Ranking der Suchmaschinen-Software "Solr". Solr verwendet hauptsächlich die Textähnlichkeit zwischen dem Suchbegriff und den Dokument-Metadaten, um die Relevanz zu bestimmen. Mehr Informationen dazu finden sie auf dieser Seite.
Warum werden in einer Knowledge Map zur Stichwortsuche nur die 100 relevantesten Dokumente angezeigt?
Wir wollen die Anzahl der Dokumente überschaubar halten. 100 Dokumente sind bereits die 10-fache Menge die auf einer Standard-Suchergebnis-Seite angezeigt werden. Um tiefer in ein Thema einzutauchen, können Sie eine spezifischere Suchanfrage stellen. Sollten sie alle Dokumente zu einem Stichwort anzeigen wollen, verwenden Sie bitte den Streamgraph.
Wie werden die Dokumente in Bereiche aufgeteilt?
Die Gruppierung der Artikel basiert auf den Dokument-Metadaten. Wir verwenden Titel und Schlagwörter, um eine Matrix für das gleichzeitige Auftreten von Wörtern zwischen Dokumentenzu erstellen. Auf diese Matrix wenden wir Clustering- und Layout-Algorithmen an. Die Beschriftungen für die Bereiche (Blasen) werden aus den Schlagworten der Artikel in diesem Bereich generiert. Mehr Informationen finden Sie in diesem Artikel.
Hat die Lage der Bereiche (Blasen) und Dokumente innerhalb eines Bereichs (Blase) eine spezielle Bedeutung?
- Die Nähe von Bereichen impliziert thematische Ähnlichkeit. Je näher zwei Bereiche auf der Knowledge Map platziert sind, desto ähnlicher sind sie sich thematisch. Überlappen zwei Bereiche bedeutet dies nicht, dass diese Bereiche dieselben Dokumente enthalten. Dokumente werden immer nur einem Bereich zugeordnet.
- Die Zentralität der Bereiche (Blasen) impliziert die thematische Ähnlichkeit bezogen auf die gesamte Knowledge Map; dies hat nichts mit der Wichtigkeit eines Bereichs zu tun. Je zentraler ein Bereich (Blase) in der Knowledge Map liegt, desto mehr hat diesen thematisch mit allen restlichen Bereichen etwas gemeinsam.
Dabei gilt zu beachten, dass die Lage der Bereiche (Blasen) innerhalb einer Knowledge Map lediglich ein Hinweis auf thematische Ähnlichkeit sind. Die Anordnung wird beim Laden entzerrt um die Knowledge Map besser lesbar zu gestalten. Die Lage eines Dokuments innerhalb eines Bereichs (Blase) hat keine Bedeutung. Um Überlappungen zu vermeiden wurden diese neu angeordnet. Mehr Informationen finden Sie in diesem Artikel.
Warum sind manche Visualisierungen besser als andere?
Beide Visualisierungen (Knowledge Map und Streamgraph) sind abhängig von den Ergebnissen, die zu einer Suche gefunden werden. Wenn es z.B. nur wenige Dokumente zu einem Suchbegriff gibt oder wenn zu einem Dokument nur wenige Metadaten vorhanden sind, dann hat dies auch einen Einfluss auf die Qualität der Visualisierung. Die Metadaten werden kontinuierlich von den Bibliothekar*innen der BAS:IS aktualisiert und verbessert. Sollten Sie Fehler finden, schreiben Sie bitte eine E-Mail an: linkedcat@oeaw.ac.at.
Warum sind manche Textauszüge fehlerhaft?
Die Scans der Sitzungsberichte wurden mittels automatisierter Texterkennung (Optical Character Recognition - OCR) in maschinenlesbare Texte umgewandelt. Damit sind diese Texte durchsuchbar und Sie können bspw. Abschnitte aus den PDFs kopieren. Leider kann es bei diesem Verfahren aber zu Fehlern in der Texterkennung kommen.